So not entirely music related, but my don’t-use-reddit policy and this looking like the closest not entirely dead community has led me to post sooo…
I have an audio question about recording levels. I’m doing voice-over stuff for some really bad Youtube videos I’d like to make and it never sounds remotely good.
I get that the recording volume should be just the green side of clipping, but how do you take a track, and then add it to other tracks and balance the whole thing to not sound like ass?
It always seems that it’s either too loud or too quiet and I’m baffled as to how to tweak the mix correctly so that things sound right.
You must log in or register to comment.
Sounds like you need ducking. Side chain compression on the audio tracks keyed to your voiceover track.
People are going at this with a music production mindset, and while not wrong, I think it’s overkill and it might not be the result you want.
At the studio I work at, where we do voiceovers and dubbing, the mix is made by manually adjusting the levels while listening to it. That’s it. If the voice is too loud, move the fader down a bit; if it’s too quiet, move the fader up. No compression needed, just volume automation.
We do use some sidechaining but only for narrator.
You can also check the overall levels to see if your LUFS and true peak and all that is correct; but if you’re doing it for yourself, just keep the original audio at around -18dB, and that should give you margin for the voiceover (if the voiceover peaks above -1dB and it still feels too quiet, you may need to go a bit lower with the background).
I suggest you first think about what your sources are? What microphones? Does it match the voice? How’s the proximity? How does the room sound? Can you hear the room? Not saying this is your case and it sounds harsher than what it means, but the old saying of “shit in, shit out” is always a good place to start. Check your sources.
It also sounds like compression might be needed on the vocal to level it. That way, whether you duck the BG music to the vocal, or have just vocals alone, things are even. EQ also plays a part in where stuff fits in the whole spectrum of sound.
Keep in mind that if the dynamics and equalization is off on each individual track, it’s trickier to balance stuff out bc it’s kinda untamed.
Seconding track leveling and compression, especially if the parts are recorded separately or you’re not used to live performance.
(This isn’t to say that track level dynamics aren’t important, especially in non-pop music)
Solution update:
Lots of advice, and I found what I needed: it was audio compression. This was not a thing I had a clue existed, but it’s exactly what I needed.
Resolve does it natively, and having it compress the voice track, and then adding some ducking and fiddling with the volume levels resulted in closer (if not exactly) to what I was expecting/needing.
Like, that was 90% of the problem, and I’m sure the last 10% is simply a skill issue and I’ll get it sorted out.
Thanks for telling me what I should be looking for, since it’s kinda hard to find the answer for something when you don’t know what the thing you need is called.
In hindsight a compressor should have definitely been my first suggestion. There’s a tendancy to over-complicate things. Glad it worked out for you. Feel free to post any other audio questions you may encounter here.
Oh, I don’t know if this is an issue for you, but a de-esser is another thing you may not have heard of that can make a little difference.
Not necessarily my area (though definitely welcome) but what are you mixing your voiceovers with? Background music? What are you finding is not sounding good? Are you looking at frequency ranges?
Yeah, it’s a recorded audio track of the voice over being mixed (or attempted anyway) with some mellow background music because I wasn’t happy with how quiet everything was. The nVidia broadcast noise removal/echo removal is really damn good, but it leads to creepy sounding videos because it’s so dang quiet.
The main issue is that the audio doesn’t sound good on varying headphones/devices/etc once they’re added to the Davinci Resolve project, mixed, and then rendered into a video.
Don’t know if it’s Resolve being the problem, me being the problem, or just some fundamental understanding I lack with how you should mix two tracks, where one is very much intended to be audible, but substantially lower volume than the other.
I’m all for adding added steps if I can get the audio to be mixed and audible at a variety of volume ranges and devices.
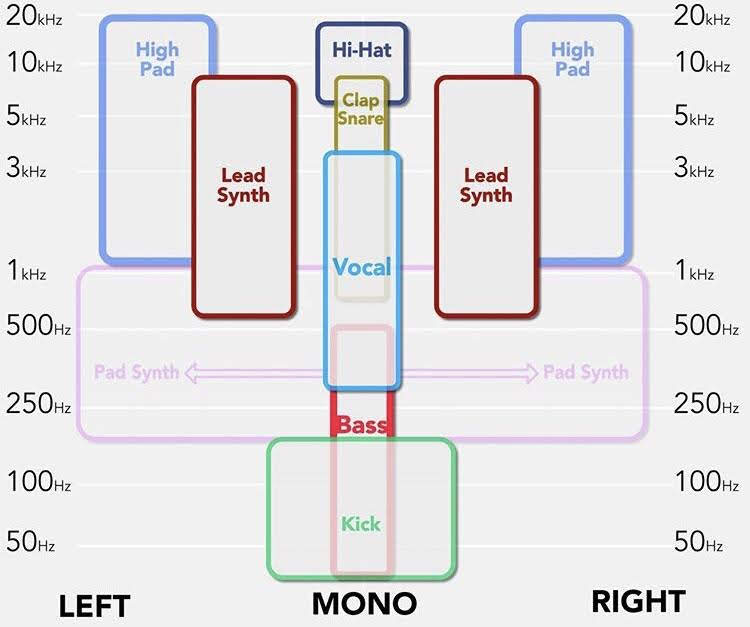
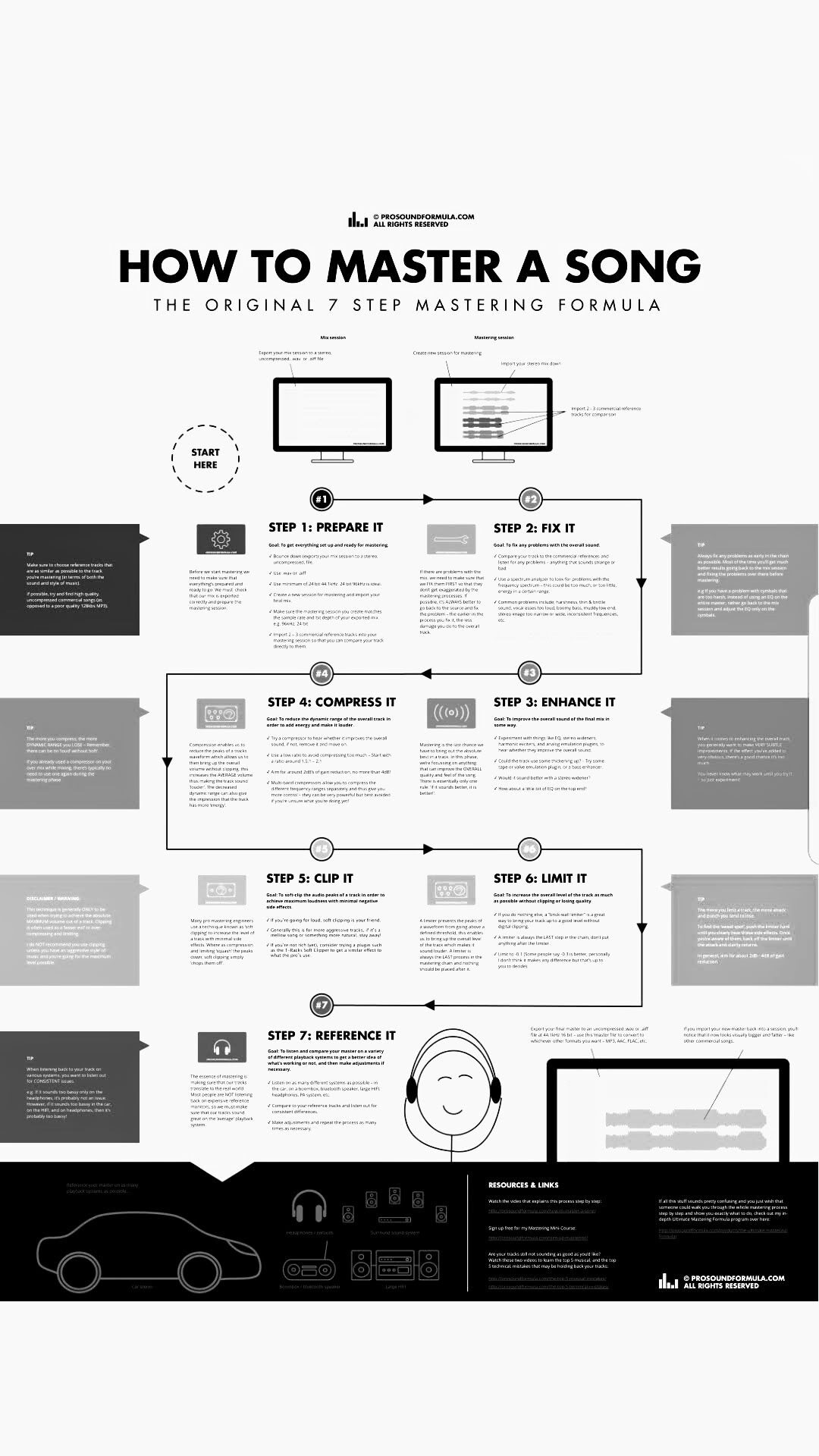
I’ve included some images that, no matter how you proceed, should give you a better understanding of frequencies, dB levels, and how to mix better.
Mixing voice into an already recorded track would need more then just volume level adjustments.
There’s a bunch of methods, some better, depending on your os, software, gear, etc.
I’d be happy to help get you directed to some software based on your available setup and ability. (there’s an almost infinite supply of free stuff out there for every need)
Assuming you can find a basic daw or audio software you can do the following:
The most basic way to mix vocals would be steps 1 through 4. 1 through 6 for a sharper, fuller sound. All of them for overkill but possibly the best result.
-
Set a ceiling (the Max volume of the mix) of maybe -4db (this allows you to increase overall volume later) using a compressor or limiter.
-
Vocals should almost always be recorded and mixed in mono. Centered. Compress / limit Around -9db max
-
Stereo separate the music/background track. A mid-side stereo mixer would make it simple. They split the low,mid,high frequencies to sides or middle, effectively giving room for each to breathe. This track is likely already mastered so no compression, just limit to around -12db.
-
Listen to mix. Sound OK?
Listen in mono. Sound OK?
You’re done! -
I would EQ both. Cutting a space for the vocal to sit in the existing music / background track in the vocal range.
And limiting the frequency range of the vocal track. -
Compressing it would be a good next step - Another post mentioned you could sidechain/duck. I agree. Have the vocal trigger compression on the background track. A multiband/dynamic eq compressor would be ideal.
-
Then eq again for clarity and depth.
-
Increase volume / compress up to 0db.
(Also, Composing Gloves on YouTube is amazing for theory and practical application. They use fl studio, but the mixing/mastering theory/methods are universal principals of mixing)


-
Non-expert here, but something I’ve read about popped in my head reading this, and I suspect it may be part of the solution you’re looking for.
Look up audio ducking. My understanding is that ducking means dynamically lowering the volume of background tracks when you want a voiceover (or other track) to be in the forefront. It looks like Davinci has settings to do ducking automatically.
Yes, my instinct would be to look at the freq range of the vocal track and try having that range of frequencies in the backing track duck out when voice is present.
If you could send me the individual tracks and the mix you’re unhappy with it would help identify the issue. And would probably make good mxijg practice for me too tbh.
Compressors and complementary EQing will solve 90% of your problems. The rest is the subjective stuff.