Warning: Some posts on this platform may contain adult material intended for mature audiences only. Viewer discretion is advised. By clicking ‘Continue’, you confirm that you are 18 years or older and consent to viewing explicit content.
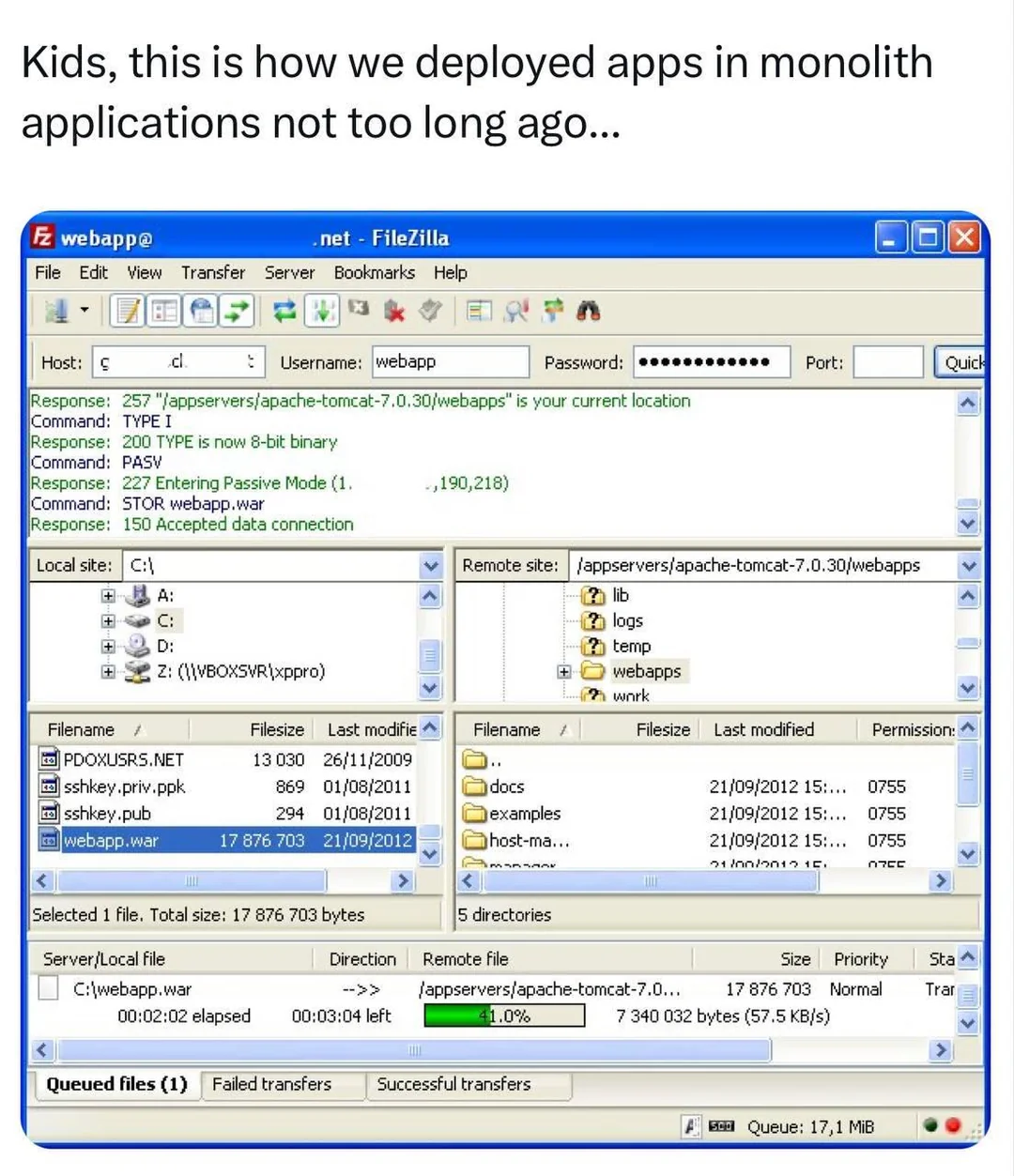
I manage a stack like this, we have dedicated hardware running a steady state of backend processing, but scale into AWS if there’s a surge in realtime processing needed and we don’t have the hardware. We also had an outage in our on prem datacenter once which was expensive for us (I assume an insurance claim was made), but scaling to AWS was almost automatic, and the impact was minimal for a full datacenter outage.
If we wanted to optimize even more, I’m sure we could scale into Azure depending on server costs when spot pricing is higher in AWS. The moral of the story is to not get too locked into any one provider and utilize some of the abstraction layers so that AWS, Azure, etc are just targets that you can shop around for by default, without having to scramble.
{kind=link}
I manage a stack like this, we have dedicated hardware running a steady state of backend processing, but scale into AWS if there’s a surge in realtime processing needed and we don’t have the hardware. We also had an outage in our on prem datacenter once which was expensive for us (I assume an insurance claim was made), but scaling to AWS was almost automatic, and the impact was minimal for a full datacenter outage.
If we wanted to optimize even more, I’m sure we could scale into Azure depending on server costs when spot pricing is higher in AWS. The moral of the story is to not get too locked into any one provider and utilize some of the abstraction layers so that AWS, Azure, etc are just targets that you can shop around for by default, without having to scramble.